
Data quality is paramount for educated decision-making for businesses, governments, academics and individuals alike. When data is not complete, its analyses lead to biased results which could have far-reaching consequences. PATSTAT, a global database of patent statistics published by European Patent Office (EPO), draws on data from over 100 million patents from 196 patent offices all over the world. Naturally, owing to the diverse variety of data sources and different data collection methods, the database struggles with missing data on crucial information such as the patent’s country code and technology classification. For example, a meagre 0.05% of patents filed in Japan in 1990 have information on inventor’s country code. Given the huge volume of applications received by different patent offices and the importance of this data in measuring innovation capabilities across countries, it becomes imperative to impute the missing data.
Using the latest Spring 2022 edition of PATSTAT, a study by ACI imputes the missing information on country code reflecting where the invention belongs and where it originated, and technology classification variables – International Patent Classification (IPC), Technical Field and NACE2 code. The three technology classifications divide the patent technology into sections/fields with different levels of aggregation. The authors reassess and further improve on the method advocated by Rassenfosse and Seliger (2021) using patent family as an anchor for imputation. All the patent applications with almost identical technical content filed at different patent offices form a patent family. The date of the first patent application within a family is called the ‘priority date’ and all members of a family have the same priority. The authors believe that “applications within a family share the same inventor(s)/applicant(s) and belong to the same IPC”.
The study considers all the patents filed before 2022 at patent offices in OECD, EU and BRICS countries, EPO, World Intellectual Property Organization (WIPO), Switzerland and, Norway – which together constitute 92% of the world’s patent applications. First step of the imputation method begins with fetching information from the first filing of the family which is regarded as Source 1. Second, if the missing information could not be sourced from Source 1, subsequent earliest application is considered as Source 2. Similarly, the third-earliest application is regarded as Source 3 and so on. The belief is that since the patents are filed in different locations across the world, the chances of retrieving information at every subsequent step are at least independent of that of the last step. In case of technology classification, the process stops at Source 3 and the information is thereafter declared missing. In case of country code, the information is not declared missing until it is irretrievable even after the identification of Source 7. Throughout this comprehensive 7-step approach, the authors consider inventor’s, applicant’s and even patent office’s (where the patent was filed) country code as the country code of the patent. The analyses focus on families with size greater than one; to infer the country code of those with equal to one, the national patent office country code is regarded as the country code.
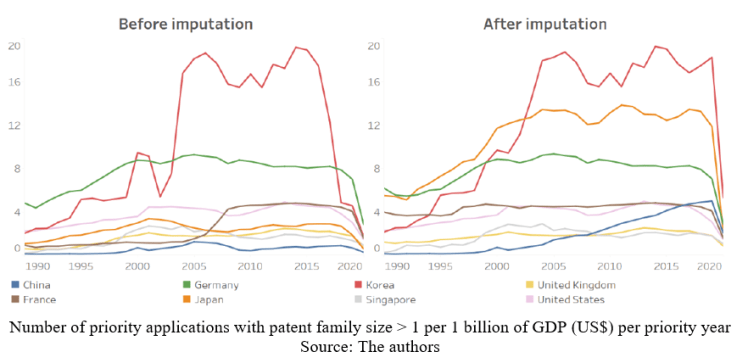
The results are impressive – almost all patent offices have 95% or higher country code coverage just after the first three steps. In particular, patent offices in the UK (in 1990) and France (in 1990 and 2000) witness an average increase of 80% in coverage of country code data. The country code coverage rate improves with each subsequent round of imputation. In case of technology classifications, while the coverage for majority of the offices was over 98%, it significantly improves for the UK patent office after browsing Sources 2 and 3. As a result, many countries record a jump in the patent quality – number of priority applications conditioned on patent family size being greater than one – after the imputation. Patent data reflects a country’s ability to exploit knowledge and its inventive performance, data completeness is therefore essential to guiding policy decisions in the right direction.
Researchers: Yixuan GE, Taojun XIE, Chi ZHANG
